
As I mentioned in my last post, I recently re-wrote the website and blog engine for my website. As part of that project and a different project of mine, I've been writing a lot of library code for CosmosDb and ASP.NET Core lately. One of the big things that I wanted was an easy way to log CosmosDb query details and ASP.NET Core MVC page request details.
I don't know about you but I've always found getting my logging code right to be kind of a tedious and messy process with a lot of hard-coded string values. Typically, those hard-coded strings are the "source" values for the log messages -- which class and which method is making the log call.
public class MyClass
{
public void DoSomething()
{
logger.WriteToLog("MyClass.DoSomething()", "did something");
}
}
You can make these calls a little more streamlined by using nameof but that only gets you so far. I wanted something a little more "automagical."
CallerMemberName Attribute
That "automagical" thing that I discovered is the CallerMemberName attribute. The method below is a utility method in CosmosRepository that creates a description for a query that runs against CosmosDb. Notice that the methodName parameter has a default value of empty string -- so if you call this method, you don't have to pass any value for methodName. But that parameter also has the CallerMemberName attribute attached to it, so when this method gets called, the compiler automatically drops in the name of the caller.
 [Click on image for larger view.]
[Click on image for larger view.]
So lets say that you have the following code:
public class MyClass : CosmosRepository
{
public void DoSomething()
{
// calls GetQueryDescription()
logger.WriteToLog("MyClass.DoSomething()", GetQueryDescription());
}
}
When the logger.WriteToLog() line gets executed, it passes the value returned from GetQueryDescription() as the log message! I think that's unbelievably cool!
A Little Side-Note About CallerMemberName
As a disclaimer, I've been writing using C# for a long, long time. Decades. And when I discovered this attribute, I figured it was something new that had only recently been introduced.
Nope. Not new at all.
CallerMemberName was introduced as part of .NET Framework 4.5 in 2012. When .NET Core 1.0 dropped in 2016, it was there on the first day. I literally had never heard of this before and it blew my mind that I'd never known about it.
Getting Fancier (and Lazy-er) with Extension Methods
So using that attribute saved me from having to supply one parameter value. When I started adding logging to my website's content management system (CMS), I wanted to log things like page view, blog post views, and errors. Those calls were super repetitive and I wanted to see if I could get even more streamlined (read: lazy).
All of my controller classes extend from a common abstract base class named CmsControllerBase. One of the key features of CmsControllerBase is hanging on to a repository class for writing HTTP traffic information to CosmosDb, and that repository is exposed as protected ITrafficLogRepository TrafficLogRepository.
 [Click on image for larger view.]
[Click on image for larger view.]
The upside of this is that I can create a C# extension method for the logging calls and those logging calls will have access to the controller. The extension method below is for logging HTTP 404 Not Found results. It takes the calling controller as an argument via this CmsControllerBase controller. It also takes the calling method name that uses CallerMemberName.
 [Click on image for larger view.]
[Click on image for larger view.]
Then in my controller code, that means that logging an HTTP Not Found is just a matter of one empty method call (see below).
 [Click on image for larger view.]
[Click on image for larger view.]
This wasn't the only extension method for logging. I also created utility extension methods for recording successful web traffic (HTTP 200), bad requests (HTTP 400), and errors (HTTP 500).
 [Click on image for larger view.]
[Click on image for larger view.]
Once I had these, adding the logging calls was a simple matter of pasting in a bunch of single-line method calls without having to fiddle with any argument values.
Summary
If you're looking to simplify your logging calls, the CallerMemberName attribute is a powerful tool that can save you a lot of time and effort. By automatically inserting the name of the calling method, it eliminates the need for hard-coded strings and reduces the risk of errors. This attribute is especially useful for creating more maintainable and readable code, making your logging process more efficient and less prone to mistakes. Give it a try and see how it can streamline your logging practices.
About the Author
Benjamin Day is a consultant, trainer and author specializing in software development, project management and leadership.
Posted by Benjamin Day on 01/21/20250 comments

AI's transformation of software development sees more and more groundbreaking tools and frameworks empowering developers to build more intelligent and efficient applications. Among these advancements is the ability to integrate large language models (LLMs), vectorized data, and robust cloud-based services to create AI copilots that can transform how users interact with software.
For VSLive! blog readers, of course, that means using Microsoft tooling like Semantic Kernel with Azure OpenAI Service and Azure Cosmos DB -- with the help of .NET Aspire.
And that's what will be used in an upcoming session titled "Building AI Copilots: Integrate Semantic Kernel, Azure OpenAI, and Azure Cosmos DB with .NET Aspire," presented by Justine Cocchi, a Senior Program Manager at Microsoft, during the Visual Studio Live! developer conference in Las Vegas March 10-14. This introductory-to-intermediate session offers attendees a hands-on guide to building an AI-powered application step-by-step. From generating embeddings on user input to leveraging Azure Cosmos DB's cutting-edge DiskANN vector indexing and search capabilities, the session is designed to demystify the process of building Generative AI applications using a Retrieval-Augmented Generation (RAG) pattern.
 "We'll walk through how .NET Aspire provides consistent client initialization patterns for Azure Cosmos DB and Azure OpenAI as well as how the Aspire dashboard simplifies debugging in development."
"We'll walk through how .NET Aspire provides consistent client initialization patterns for Azure Cosmos DB and Azure OpenAI as well as how the Aspire dashboard simplifies debugging in development."
Justine Cocchi, Senior Program Manager, Microsoft
Cocchi's session aims to equip developers with actionable insights to seamlessly integrate the tools mentioned above into .NET Aspire applications. Microsoft has been heavily pushing .NET Aspire lately, a cloud-ready stack for building observable, production-ready, distributed, cloud-native applications with .NET, helping devs with orchestration, components, tooling, service discovery, deployment and more.
 Source: Microsoft
Source: Microsoft
Attendees are promised to gain a comprehensive understanding of the foundational concepts, explore practical techniques for enhancing scalability and performance, and leave with a solid framework to create their own AI copilots.
Ahead of the event, we caught up with Cocchi to learn more about the technology, the session and how attendees can prepare for it.
VSLive! What inspired you to present a session on this topic?
Cocchi: Generative AI applications have been trending for some time now, and I wanted to walk attendees through some best practices. From choosing a database that can seamlessly scale as your app grows like Azure Cosmos DB, using frameworks that help you manage infrastructure and code like .NET Aspire and Semantic Kernel, to following patterns that allow for contextually accurate results like the RAG pattern -- there are many factors that make a successful AI application.
How does .NET Aspire interoperate with the core components and functionalities of Semantic Kernel, Azure OpenAI, and Azure Cosmos DB to facilitate the development of AI copilots?
.NET Aspire is helpful while developing and deploying any production-grade .NET application, and AI copilots are no different.
We'll walk through how .NET Aspire provides consistent client initialization patterns for Azure Cosmos DB and Azure OpenAI as well as how the Aspire dashboard simplifies debugging in development.
How do Semantic Kernel and .NET Aspire specifically work together?
Semantic Kernel and .NET Aspire are both orchestration frameworks that can help you manage your application. While Semantic Kernel helps orchestrate the AI components in your code, .NET Aspire is useful for managing the service dependencies and various projects in your solution. These two components work together to ensure you can focus energy building your business logic instead of worrying about how to set up your project.
What common challenges might developers face when integrating these technologies?
One of the challenges is keeping up with quickly changing libraries and AI LLMs. Relying on frameworks like Semantic Kernel to help you orchestrate the AI components in your application instead of writing all the functionality in native SDKs can help reduce the burden of underlying API changes. Knowing what tool to use when is critical to maintaining performance while reducing developer toil.
How can developers optimize the performance and scalability of AI copilots built with this technology stack, particularly concerning data processing and response times?
There are a few ways to ensure performance remains high as your application scales. It's critical to pick a database that can keep response times low as more data is added. We'll talk about DiskANN vector indexing in Azure Cosmos DB, which is built for performant vector searches over large data volumes. Slow response times can also come from the LLM generating chat completions, especially when large amounts of context are passed in. We'll dig into managing the amount of chat context sent with each new request and patterns for semantic caching to reduce overall response times on repeated questions.
What resources would you recommend for developers to get up to speed in this space and prepare for your session?
There are many great resources to learn about building copilots with Azure Cosmos DB, Azure OpenAI, Semantic Kernel and .NET Aspire. The session is based on the demo application in this repository. You can also refer to the AI Samples Gallery and the Azure Cosmos DB vector search documentation.
Save $400 when you register for VSLive! Las Vegas Developer Training Conference (March 10-14) by the Super Early Bird savings deadline of Jan. 17.
Posted by David Ramel on 01/13/20250 comments

I recently decided that my website needed some love and maintenance. I'd been hosting it using WordPress for a zillion years and I'd started getting fed up with how much it was costing me to run it. So I did what every busy developer does -- I decided to write my own content management system / blog engine using Cosmos DB and ASP.NET Core MVC. It came out pretty darned good and my ASP.NET MVC skills got a workout and a refresher.
One big thing I learned when I was writing all the search engine optimization (SEO) code was about sections and the @RenderSection helper method.
Why Would I Care about @RenderSection?
In order to get your site to be SEO compliant and to help your site and content to show up in search engines, there are a whole bunch of values that you'll want to put into the HTML of your webpages. Lots of these values are part of the Open Graph Protocol and are the machine-readable metadata that a search engine will use to "understand" your content. These values should be part of the <head> tag of your HTML page and show up as <meta> tags.
Some of the values that I'm using on my website are:
- og:site_name -- name of the website
- og:title -- the title of the page or blog post
- og:description -- description of the website or an excerpt of a blog post
- og:type -- type of content (website, article, other)
- og:image -- image for the page or blog post
The image below is a screenshot of the meta tags that I'm setting on my home page. As you can see, there's kind of a lot of them and they all show up in the <head> tag.
 [Click on image for larger view.]
[Click on image for larger view.]
If this were a static site, I'd just put the values that I need in the various hard-coded html files for my site. But this is a dynamic page and the meta values are going to change a lot from page to page and blog post to blog post.
The part that was tripping me up was that the values needed to be in the <head> tag.
A Little Bit About the Structure of an ASP.NET Core MVC Application
In order to point out why getting values into the <head> tag was a problem, let me just pause for a moment to review the structure of an ASP.NET Core MVC View. The views are all the *.cshtml files that live in your web project. These cshtml files use a templating syntax called Razor that allows you to mingle C# code and HTML markup that gets turned in to rendered HTML that shows up in your browser.
So far so good.
The cshtml/razor/MVC syntax creates a hierarchy of these views that all work together to allow you to reuse logic and HTML so that you avoid tons of duplicated code. Here's an example. Let's say that I want to display a blog post. The display logic for a blog post lives in Entry.cshtml and when it gets run, the MVC app knows that Entry is only part of the display logic and that it also has to render _Layout.cshtml, too.
 [Click on image for larger view.]
[Click on image for larger view.]
The _Layout.cshtml file contains all the basic structure of a web page like the tags, the <html> tags, the <body>, and also the <head> tag and its contents. It also has a call to @RenderBody and this is where the contents of Entry.cshtml gets dropped in in order to make a fully rendered webpage.
 [Click on image for larger view.]
[Click on image for larger view.]
My Problem: How Do I Get Dynamic Content from a View into _Layout.cshtml?
Back to my problem. I need to be able to generate those "og:" <meta> values and make them show up in the <head> tag. The Entry.cshtml view will have access to the information that should be in the those values but the problem is that the actual tag lives in a totally different file. So how to get those <meta> values but the problem is that the actual <head> tag lives in a totally different file. So how to get those <meta> tag values from Entry.cshtml to the <head> tag in _Layout.cshtml?
The Answer: Sections and @RenderSection
Razor and cshtml to the rescue! It turns out that you can define something called a section that allows you to pass content from the child view to the layout view. All you need to do is to put a @RenderSection directive wherever you want that content to show up. In this case (see below), I put a @RenderSection called HeadContent inside of the <head> tag of _Layout.cshtml. This basically just says to the templating engine, "if you've got content for this section, drop it here." I'm also marking it as required = false meaning that if there's no content supplied, to just leave this section as blank.
 [Click on image for larger view.]
[Click on image for larger view.]
Over in my Entry.cshtml view, you can use the @section directive to set all the values that should show up in the section. So as you can see below, Entry.cshtml has access to a BlogEntry class that contains all the data for a blog post via the @model directive. Once I've got that data, it no big deal to just drop in the values.
 [Click on image for larger view.]
[Click on image for larger view.]
Then at runtime, all the generated <meta> data from the entry, shows up in the <head> tag. All I needed to do was make sure that the name I supplied on my @section matches the name supplied in the @RenderSection.
- @section HeadContent
- @RenderSection("HeadContent", required: false)
Summary
In this post, we explored how to leverage @RenderSection in ASP.NET Core MVC to solve layout-related challenges and create dynamic, flexible web pages. Whether you're building a custom blog engine or enhancing your web application's structure, sections provide a clean, modular approach to content management. By integrating sections effectively, you can simplify your layout design and unlock more maintainable solutions for rendering dynamic content.
About the Author
Benjamin Day is a consultant, trainer and author specializing in software development, project management and leadership.
Posted by Benjamin Day on 12/17/20240 comments

.NET 9 was introduced in November with claims of speed, efficiency, and cross-platform capabilities to provide Microsoft-centric developers with even more flexibility and power to write modern applications.
That's done with the help of new APIs that have been introduced by the Microsoft dev team in recent .NET versions, with .NET 9 providing new APIs for .NET Aspire, ASP.NET Core and other properties that touch upon functionality regarding OpenAI, garbage collection, authentication and authorization and much more.
 [Click on image for larger view.] .NET 9 Highlights (source: .NET Conf screenshot).
[Click on image for larger view.] .NET 9 Highlights (source: .NET Conf screenshot).
To help developers get a handle on the new .NET 9 functionality, specifically what APIs have been added to recent .NET versions, expert Microsoft MVP Jason Bock will review new features and APIs at the Visual Studio Live! developer conference coming to Las Vegas in March.
Aptly titled "What's New in Modern .NET Library APIs," this is an intermediate session lasting 75 minutes in which attendees are promised to learn:
- What functionality .NET provides
- New features in the latest version of .NET
- Insights in staying on top of new runtime versions
We caught up with Bock, a staff software engineer at Rocket Mortgage, to learn more about his upcoming session.
VSLive! What inspired you to present a session on this topic?
Bock: I've always been interested in watching the evolution of .NET.
 "The API surface is .NET is vast, providing functionality for a wide variety of concerns, from as small as generating a unique identifier to creating a web application. In each version, there's always something new to dive into and see what it does."
"The API surface is .NET is vast, providing functionality for a wide variety of concerns, from as small as generating a unique identifier to creating a web application. In each version, there's always something new to dive into and see what it does."
Jason Bock, Staff Software Engineer, Rocket Mortgage
The API surface is .NET is vast, providing functionality for a wide variety of concerns, from as small as generating a unique identifier to creating a web application. In each version, there's always something new to dive into and see what it does. Even if it may not of interest me now, it might be something I need in the future. I want to learn about these features and share with others what I've found.
What is just one of the most notable API additions in .NET 9 that serve to enhance developer productivity?
While the focus is usually on "big name" items like .NET MAUI and .NET Aspire, I personally am interested in those general-purpose APIs that I can use no matter what application I'm building or framework I'm using. For example, there's a new type called CompositeFormat that is useful when you want to use a string with format "holes" in them that will get filled in later, like in a logging call. CompositeFormat can make this scenario a bit more performant. Task.WhenEach() is a new API that will let you enumerate a set of tasks based on when the tasks complete. Finally, the Base64Url class -- a type used for Base64 encoding -- no longer requires a separate package to be installed from NuGet. It's "in the box" with .NET 9.
What are a couple of top considerations developers should keep in mind when integrating these new APIs into existing .NET applications?
.NET has become an extremely stable platform from an upgrade perspective. Gone are the days where moving from one version of the .NET Framework to a new one may require a significant investment of time addressing breaking changes and versioning issues. If you're moving from a previous version of .NET to .NET 9, the transition should be very smooth. That doesn't mean it'll always issue-free, but keeping on pace with new .NET versions is far less of a burden than it used to be.
How do the new APIs in .NET 9 align with current trends in cloud-native development and microservices architecture?
There are definitely changes related to AI. There are more packages being released by Microsoft that make the usage of LLMs and other AI-related technologies easier to consume. .NET Aspire is a new API that is all about simplifying and empowering developers working on cloud-based applications. And underneath it all, there are constant performance improvements in each version of .NET to improve the performance of modern applications targeting .NET.
What resources or best practices would you recommend for developers to get up to speed with these new APIs and prepare for your session?
Microsoft typically provides a "what's new" article summarizing all of the changes that are done with a major release. .NET 9 is no different -- you can find that resource here. If you're interesting in diving deeper, there are Markdown diff files that show exactly what has changed from version to version. Those release notes exist here.
Note: Those wishing to attend the conference can save hundreds of dollars by registering early, according to the event's pricing page. "Save $500 when you Register by the Cyber Savings deadline of Dec. 13," said the organizer of the event.
Posted by David Ramel on 12/12/20240 comments

Wait! This won't be boring! Yes, I know -- this probably isn't the most exciting topic ever, but I ran into some problems this week and I actually learned some cool stuff about nullability in C# and the compiler.
The issue I was running into was member variable initialization inside of a class. WAIT! Please don't quit on this article! I swear it gets better! I started off with a simple class, but it had complex initialization logic that involved multiple method calls and a bunch of calculations. Simple enough but I couldn't get it to compile because I kept getting nullability errors from the compiler.
Stick with me and I'll talk you through the fixes I used to keep the compiler happy.
Simple Class. Complex Logic.
The sample code I'm going to use is going to be much simpler, but it'll demonstrate the problems. Let's start with a C# class for a Person that has two string properties: FirstName and LastName. Looking at the code below, right from the very beginning I've got two compilation errors on those properties. Since strings are null by default, this is failing compilation because I'm not initializing the property values.
div>
 [Click on image for larger view.]
[Click on image for larger view.]
Figure 1: Person Class with Two Compile Errors
Now it would be simple enough in this case to just set the values either using a constructor or by using a property initializer. Just tag "= string.Empty;" onto the end of each of those properties and the compiler warning goes away.
 [Click on image for larger view.]
[Click on image for larger view.]
Figure 2: Fixing the Compile Problem Using Property Initializers
This works in a simple example like this, but in my production application code, the logic wasn't so straightforward -- and I needed to use the initialization logic in multiple places.
Use an Initialization Method
Since I needed code reuse and wanted avoid duplicate code, my ideal solution is to use an Initialize() method that I call from the constructor.
 [Click on image for larger view.]
[Click on image for larger view.]
Figure 3: Initialize() Method but Compilation Still Fails
The problem is that once I do this, I'm getting a compile error.
Non-nullable property 'FirstName' must contain a non-null value when exiting constructor. Consider adding the 'required' modifier or declaring the property as nullable. CS8618
This is super annoying because I know as the programmer that the Initialize() method actually is fixing the initialization problem and therefore the compile error is kind of wrong. It's not totally wrong ... but it's pretty much wrong. The problem is that I don't have a way to prove it to the compiler.
The C# 'required' Keyword: Make it Someone Else's Problem
The compile error is helpfully giving us a couple of options. Either make the property nullable or add the required keyword. Both of these "solutions" solve the problem without solving the problem -- arguably they just move the problem somewhere else and make it someone else's problem.
If we make the property nullable, we get properties that look like this:
public string? FirstName { get; set; }
That "?" at the end of the string type means that anyone who uses this property now has to worry that the value could be null. That spreads a lot of null-checking logic throughout the app and that stinks. Kind of misses the point of having compiler null checks, too.
The other suggestion is to use the required keyword. This was something that I didn't know about. It was added as part of C# 11 back in November of 2022 so it's still a somewhat new feature in the language.
If you add the required keyword to the properties, it means that the caller to this class must supply a value as part of the call. Put another way, anyone who new's up an instance of Person would need to supply the values for FirstName and LastName.
 [Click on image for larger view.]
[Click on image for larger view.]
Figure 4: Adding the 'required' Keyword to the FirstName and LastName Properties
This solves the compile problem in Person.cs but -- like I said -- it kind of moves the problem somewhere else. Let's say I have a class called PersonService that creates an instance of Person. When PersonService creates that instance of Person (see Figure 5), it needs to pass values for FirstName and LastName. Once again, in a simple scenario like this, it isn't all that onerous -- but if the logic for initialization is complex, this is a recipe for sprawling code duplication.
 [Click on image for larger view.]
[Click on image for larger view.]
Figure 5: The 'required' Keyword Means You Must Supply Values when You Construct the Class
This moves the problem out of the Person class and potentially spreads the problem around in the rest of the code. This violates not only best practices of object-orientation but also guidelines for maintainability.
Not my favorite solution.
Show the Compiler Who's Boss: The [NotNullWhen] Attribute
Let's go back to that Initialize() method from a little while back. In my actual production application, I had complex initialization logic that I needed to use in a couple of different places and that made this Initialize() method my preferred option. But it also caused problems because the compiler didn't officially know that I was actually indeed initializing the FirstName and LastName property values.
 [Click on image for larger view.]
[Click on image for larger view.]
Figure 6: The Compiler Doesn't Know that Initialize() Actually Initializes
The solution here is to add an attribute called [MemberNotNull]. It's part of the System.Diagnostics.CodeAnalysis namespace and what it does is tell the compiler what we're achieving in the Initialize() method -- in this case, actually setting FirstName and LastName to non-null values.
In the code sample below (Figure 7), I apply the [MemberNotNull] attribute and pass it the names of the FirstName and LastName properties. Once I do that, I don't have any compiler errors complaining about null values and initialization and I also get to reuse my Initialize() method code. Just by adding this attribute, it saves me from having to pile all my initialization logic into my constructor just to keep the compiler happy.
![Figure 7: The [MemberNotNull] Attribute Fixes the Compile Problem](~/media/ECG/VSLive/Blogs/2024/11/benday_nov24_13_s.ashx) [Click on image for larger view.]
[Click on image for larger view.]
Figure 7: The [MemberNotNull] Attribute Fixes the Compile Problems
By the way, there are also some other nullability hint attributes that you might want to check out: [NotNull], [NotNullWhen], and [MemberNotNullWhen].
Summary
Hopefully, you agree that this wasn't that boring and hopefully you learned something. If you care about your compile time null checks (and you should), you sometimes have to get creative about your initialization logic. You can either pile all your init code into the constructor so that the C# compiler understands the logic by default, you can add the required keyword to mandate that callers pass you the required values, or you can tell the compiler to chill out by using [MemberNotNull].
About the Author
Benjamin Day is a consultant, trainer and author specializing in software development, project management and leadership.
Posted by Benjamin Day on 11/18/20240 comments

Here's a scenario I ran into just last week. I was working on some code to edit PowerPoint PPTX files using C# and the OpenXML libraries. If you've ever tried using them before, you know that the OpenXML libraries are impossibly complex and nearly impossible to understand. And as much as I might have wanted to keep my code simple, I was losing and the complexity was growing.
The bugs I was getting were pretty complex, too. I'd put a bunch breakpoints in my code and then I'd be using the debug visualization tools in Visual Studio to try to figure out what was going wrong. But the problem was the my bugs could be just about anywhere in a giant tree of objects. It was really hard to figure out what was going on just by looking at the debug windows. For example, just check out that Locals debugging window in the screenshot below. It's nested object after nested object after nested object.
 [Click on image for larger view.]
[Click on image for larger view.]
I needed to tame that debugging sprawl.
The [DebuggerDisplay] Attribute
I'm not sure how I found out about this, but there's this cool feature in Visual Studio and .NET that lets you customize how your objects appear in the debugger. It's the DebuggerDisplay attribute in System.Diagnostics. I'd never used it before because -- well -- I just assumed that it must be difficult to use.
But it turns out that it's super easy to implement. If you know how to use interpolated strings, you pretty much know how to implement the debugger display attribute.
Here's a quick review of interpolated strings. Let's say that you have three values that you want to combine into a single string: current date, a random number, and the OS version string. You could combine them using the "+" operator -- that's the old-school, original way.
Or you could combine them using string interpolation. Just put a "$" in front of the string and then wrap the variable names you want to use inside of curly braces. Done.
 [Click on image for larger view.]
[Click on image for larger view.]
Tame the Debugging Mess
Rather than try to demo this with OpenXml APIs, I'm going to introduce a more understandable example. Let's say that I have a Person class that has a property for Name and a property for PhoneNumber. Most of the time you'd probably just have a Person class with a string property for FirstName, a string property for LastName, and a string property for PhoneNumber. But since I need some complexity, I'm splitting these into separate classes so that I get an object model:
 [Click on image for larger view.]
[Click on image for larger view.]
To keep adding complexity, let's say that I'm writing my own PersonCollection class and I'm trying to write a unit test to make sure that when I "foreach" over the PersonCollection, that the objects are always returned in alphabetical order by name.
The test is failing and I'm not sure why, so I put a breakpoint on the code and go to take a look in the debugger:
 [Click on image for larger view.]
[Click on image for larger view.]
When I look at the "actual" collection variable in the debugger, I see a list of 5 objects but I can't see the values:
 [Click on image for larger view.]
[Click on image for larger view.]
In order to figure out what the values are, I need to start expanding properties in the watch window. That gives me something that looks like this:
 [Click on image for larger view.]
[Click on image for larger view.]
So, I can see that the values are clearly not sorted by last name but the next time that I run this code, it's going to show me the original view and I'm going to have to click a bunch of times to get to the data.
Add the DebuggerDisplay Attribute
What would be a lot nicer would be a simple view of my Person properties right in the debugger when I'm looking at that collection. This is exactly what the DebuggerDisplay attribute does.
At the top of the Person class, I'll just add the DebuggerDisplay attribute and then provide it with an interpolated string describing how I'd like to visualize the data in the debugger. In this case, I want to see the LastName value, a comma, FirstName, and then the phone number.
 [Click on image for larger view.]
[Click on image for larger view.]
The next time that I run this code and hit that breakpoint, I see much more descriptive data in the Values column:
 [Click on image for larger view.]
[Click on image for larger view.]
And now I can focus on fixing my bug rather than crawling through a tree of values in the watch windows.
Conclusion
Debugging complex trees of objects can be difficult even with great debugging tools. In order to make it easier on yourself, consider adding the DebuggerDisplay attribute to those difficult-to-debug classes. DebuggerDisplay allows you to provide a view of your object in the Visual Studio debugger windows that have exactly the data you need to see in order to fix your problems.
If you'd like the source code for this demo, you can get it on GitHub.
About the Author
Benjamin Day is a consultant, trainer and author specializing in software development, project management and leadership.
Posted by Benjamin Day on 10/17/20240 comments
Integration testing is a crucial step in ensuring that your application behaves correctly when different components interact with one another. In ASP.NET Core, the WebApplicationFactory<TEntryPoint> class makes it easier to test your web applications by allowing you to spin up an instance of your app in-memory and run integration tests against it.
As a new author contributing to the VSLive! Blog, in my inaugural post I'll walk you through how to use WebApplicationFactory for integration testing, using a simple ASP.NET Core web application. We'll write tests to ensure that the Home page is functioning as expected. Let's dive in!
Structure of the Sample Project
This post includes a code sample with "before" and "after" versions of the code.
 [Click on image for larger view.]
[Click on image for larger view.]
In the solution shown above we have a total of four projects. We have two main projects:
- API Project: A .NET Core class library containing business logic.
- Web Project: An ASP.NET MVC application with the front-end logic.
Additionally, we have two test projects:
- Unit Tests: For testing the API logic in isolation.
- Integration Tests: For testing interactions between components, such as controllers and views, within the actual application.
We'll focus on the Integration Tests project, using WebApplicationFactory to create tests that check if the web application behaves correctly in real-world scenarios.
What Is WebApplicationFactory?
WebApplicationFactory<TEntryPoint> is a handy class in ASP.NET Core that allows us to spin up our application in-memory for testing purposes. This eliminates the need for dealing with network ports or external dependencies during testing. By creating an in-memory version of the application, we can run HTTP requests against it, similar to how we would interact with the deployed app.
Creating an Integration Test
Let's create a test to verify that the Home page of our web application displays the text "Hello World." To get started, open your Integration Test project, right-click, and add a new class. We'll name it HomeControllerFixture.
Writing the Test -- Here's the basic structure of our test:
public async void IndexContainsHelloWorld()
{
// arrange
var factory = new WebApplicationFactory<JustAnEmptyClass>();
var client = factory.CreateClient();
// act
var response = await client.GetAsync("/");
// assert
Assert.NotNull(response);
var content = await response.Content.ReadAsStringAsync();
Assert.Contains("Hello, world!", content);
Assert.True(response.IsSuccessStatusCode);
}
Breakdown of the Test:
-
Arrange:
- We create an instance of
WebApplicationFactory<JustAnEmptyClass> and use it to spin up an in-memory version of our app.
- Using
CreateClient(), we get an instance of HttpClient that knows how to communicate with the in-memory application.
-
Act:
- The
client.GetAsync("/") method makes an HTTP GET request to the root of the application, similar to navigating to the home page in a browser.
-
Assert:
- We use
EnsureSuccessStatusCode() to check if the request was successful (i.e., it returned a 200 status code).
- We then read the response content and check that it contains the string "Hello World" using
Assert.Contains().
Handling the Missing Startup Class
You might notice that we reference a class called JustAnEmptyClass instead of the Startup class. Here's why: In older ASP.NET Core projects, the Startup.cs file was used to configure the application. However, in newer project templates, the Program.cs file has taken over this role, combining the functionality of both Program and Startup. This is all part of the change to add "top-level statements" to C#. On the one hand, it simplifies the code. On the other hand, it sometimes gets in the way, and this is one of those cases where it gets in the way.
If your project actually has a Startup.cs class, then you can use that (WebApplicationFactory) instead of creating this empty, marker class. Or if you'd like to have your project actually use that style of project you can easily do that by adding the --use-program-main option to your dotnet new command when you create your project.
Unfortunately, WebApplicationFactory doesn't work directly with the Program class. The workaround is simple: create an empty class and use it as a placeholder for WebApplicationFactory. This doesn't interfere with the functionality of your application but allows you to run your tests.
// JustAnEmptyClass.cs
public class JustAnEmptyClass
{
// This class is intentionally left empty.
}
Now, when creating the factory, we reference JustAnEmptyClass instead of Startup or Program.
Running the Tests: It Fails
After writing the test, run it from your Test Explorer window. If you encounter an error that the test is missing, check that you've added the [Fact] attribute to the test method -- this tells the test framework that it's a test that should be run.
Upon running the test, it should fail initially because the home page doesn't yet contain the string "Hello World."
 [Click on image for larger view.]
[Click on image for larger view.]
Fixing the Failure
In our sample application, fixing this problem is easy enough. There's nothing on the home page that says "hello world" and therefore we just need to add that. In real-life development situations, you'll probably be testing for more complex things and you might need to write some real code.
To fix this, let's add "Hello World" to our Home page.
 [Click on image for larger view.]
[Click on image for larger view.]
- In Solution Explorer, open up the web application and go to the Views folder and then the Home folder.
- Open Index.cshtml.
- Add a paragraph containing "Hello World."
- Save the file and rerun the test.
When you've made the changes to Index.cshtml, it should look something like this:
 [Click on image for larger view.]
[Click on image for larger view.]
This time, when you run the tests, the test should pass, confirming that our integration test successfully verifies the content of the home page.
 [Click on image for larger view.]
[Click on image for larger view.]
Conclusion
Using WebApplicationFactory, we can easily write integration tests that spin up an in-memory version of our ASP.NET Core application. This allows us to test the interaction between controllers, views, and other components without needing to deploy the app to a server.
In this demo, we wrote a test to check that the Home page contains "Hello World," but you can extend this approach to test more complex scenarios like API endpoints, form submissions and more.
Posted by Benjamin Day on 09/23/20240 comments

In today's diverse development landscape, cross-platform readiness isn't just a nice-to-have -- it's a necessity. Developers are increasingly tasked with ensuring their applications run smoothly across multiple operating systems and environments. Python and Blazor, both designed with cross-platform capabilities in mind, are indispensable tools in a modern developer's toolkit.
To help developers sharpen these critical skills, Microsoft MVPs Rockford Lhotka and Eric D. Boyd are each presenting at the upcoming Live! 360 conference in Orlando, Fla. Make sure to register and catch Lhotka's three Blazor sessions and Boyd's two-day Python lab.
In the meantime, read their in-depth Microsoft Q&A where they share key takeaways from their recent presentations at the VSLive! event at Microsoft's Redmond headquarters.
Posted on 09/12/20240 comments

Devs surely do still love their SQL, but Microsoft executives are touting what they call "modern SQL" for building applications using the latest and greatest data technologies.
So what are those technologies that provide a new take on your beloved and familiar SQL? You start off with, of course, AI, specifically generative AI -- Copilots at Microsoft -- that has transformed software development along with the rest of IT. Then, being firmly in the Microsoft development camp, you add Microsoft Fabric, which is an end-to-end analytics/data platform that encompasses data movement, processing, ingestion, transformation, real-time event routing and report building.
 [Click on image for larger view.] Microsoft Fabric Architecture (source: Microsoft).
[Click on image for larger view.] Microsoft Fabric Architecture (source: Microsoft).
To learn what else you need to do, those same Microsoft executives will explain everything in a keynote session at the upcoming Visual Studio Live! developer conference being held at Microsoft HQ in Redmond, Wash., from Aug. 5-9. Specifically on hand for a keynote titled "Building Applications with the Modern SQL Using AI and Microsoft Fabric" are Asad Khan, Vice President of SQL Products and Services, Microsoft, and Bob Ward, Principal Architect, Microsoft Azure Data, Microsoft.
"We will show practical examples of how to build Generative AI applications with your data securely and at scale," they said of their keynote. "You will also learn how to use Microsoft Copilot experiences to help you build your application, manage your database, and develop SQL queries. You will also learn how to take advantage of the integration of SQL with Microsoft Fabric opening new possibilities for your data in a unified platform for analytics and AI."
We caught up with Asad and Bob to learn more about their keynote, which is scheduled for Aug. 7, 2024, from 1:30 p.m. to 2:30 p.m.
VSLive! What makes SQL still a beloved tool among developers, even with the advent of more modern data solutions?
Bob: I think first and foremost is that SQL is a platform and a brand you can rely on. SQL Server has been a leading industry database platform for decades including security, performance, and availability for all applications.
 "Whether you are a startup or a large enterprise you know you can host your data with SQL and then build any application you need using skills and tools that you know and love."
"Whether you are a startup or a large enterprise you know you can host your data with SQL and then build any application you need using skills and tools that you know and love."
Bob Ward, Principal Architect, Microsoft Azure Data, Microsoft
Whether you are a startup or a large enterprise you know you can host your data with SQL and then build any application you need using skills and tools that you know and love.
Can you summarize how Microsoft's strategy leverages SQL from ground to cloud to build robust applications?
Asad: Microsoft is a leader in the database industry to allow developers to "build once, deploy anywhere." SQL provides a unique compatible database experience for developers whether it be with Windows, Linux, Containers, Kubernetes, private, or public clouds. Since all of SQL, ground to cloud, is built on the same code base it has a common query processor, a common set of providers, tools like SSMS, and the popular T-SQL language to allow developers to have a robust and consistent experience.
How does the integration of SQL with Microsoft Fabric transform the landscape for analytics and AI projects?
Asad: Microsoft Fabric is becoming the standard for a unified data platform. It brings in so many different services including AI, analytics, data engineering, and data warehousing all under a unified user experience and storage platform called OneLake. Mirroring is a capability that allows you to bring your data from various sources in a seamless manner, including automatic change detection, into OneLake. We are excited SQL is already one of the most popular data sources for mirroring. We are just getting started with the integration between SQL and Microsoft Fabric so stay tuned.
In what ways does Microsoft Copilot streamline the process of building applications, managing databases, and developing SQL queries?
Bob: We are in the "age of Copilots" across many Microsoft products and services. I see people just using Copilots "where they live" and interact with them every day. We have a unique set of Copilot experiences for SQL including contextual aware self-help for time consuming tasks like troubleshooting and the ability to generate complex T-SQL queries using natural language. We are providing industry differentiating experiences that I believe developers and IT Pros will see how much faster they can build applications and manage databases with our Copilot skills. This is just the beginning. You will see us continue to innovate our Copilot experiences for SQL ground to cloud.
What is one practical example you will use to show how devs can build Generative AI applications with data securely and at scale?
Bob: For me it is hybrid search. You have a new "smarter and intelligent" search inside the SQL engine by combing vector data (embeddings), vector search, and the power of the SQL query processor. SQL provides methods inside the database to interact with language models in a new way for better searching using natural language. If you combine this with our new JSON data type and Regular Expression (RegEx) capabilities using T-SQL, developers can now "get smarter with their data" using the familiar skills of SQL they have known for years.
What do you hope people will take away from your keynote?
Asad: One of the big takeaways is that along with SQL's traditional strength, we believe SQL is a modern data solution for developers. Consider that SQL allows you to build any application you need with capabilities all built into the database with features like JSON, Graph, Spatial, Columnstore, and Ledger that normally require you to purchase multiple products that don't integrate with each other. Combine this now with GenAI, Microsoft Fabric, and developer interfaces like GraphQL, all within the security boundary of the engine, SQL is poised to be your modern database for the future.
Note: Those wishing to attend the conference can save hundreds of dollars by registering early, according to the event's pricing page. "Register for VSLive! at Microsoft HQ by the Early Bird deadline of July 12 to save up to $300 and secure your seat for intensive developer training at Microsoft HQ in Redmond!" said the organizer of the developer conference.
Posted by David Ramel on 07/08/20240 comments

Hey Y'all! VSLive @ Microsoft HQ is happening the first week of August. While I won't be there, my good friend Brian Randell will, and he has a couple of Copilot sessions you won't want to miss. One of the things I'm betting will come up in those sessions is GitHub Copilot Chat.
Now back in February, I wrote a post about "Getting Started with GitHub Copilot" where I introduced you to the completion feature of GitHub Copilot when you add comments to your code. I thought this would be a good time to now introduce you to GitHub Copilot Chat.
Why AI in Coding Is Important
In the rapidly evolving landscape of software development, AI has emerged as a transformative force. AI in coding is revolutionizing how developers approach problem-solving, significantly enhancing productivity and enabling the creation of more robust and efficient code. By automating repetitive tasks and providing intelligent code suggestions, AI reduces the cognitive load on developers, allowing them to focus on more complex and creative aspects of their projects. This integration of AI tools not only accelerates the development process but also fosters innovation, making it easier to experiment and iterate rapidly.
What Is GitHub Copilot Chat
GitHub Copilot Chat is a chat interface that lets you interact with GitHub Copilot, to ask and receive answers to coding-related questions within GitHub.com and supported IDEs (such as Visual Studio Code and Visual Studio 2022). While previously with GitHub Copilot, we were adding comments to our code and GitHub Copilot was then making code suggestions, GitHub Copilot Chat gives us a chat interface for working with GitHub Copilot.
This tool goes beyond simple autocomplete functionalities. GitHub Copilot Chat can generate entire code snippets, provide explanations for specific pieces of code, and even help debug errors. It acts as a conversational partner, making the coding process more interactive and intuitive. Whether you're trying to implement a new feature, understand an unfamiliar codebase, or fix a bug, Copilot Chat is designed to assist you at every step. Its ability to interpret natural language queries means you can ask for help in plain English, making it accessible to developers of all skill levels.
GitHub Copilot Chat takes the information you enter in the chat window, along with contextual information from the environment, such as the code selected or the tabs that are open in your IDE, and uses this information to help provide answers to your questions.
Getting Started with GitHub Copilot Chat
To allow you to compare and contrast using GitHub Copilot code completion vs. GitHub Copilot Chat, I thought we would take the same example from the February article, but use GitHub Copilot Chat to build it. So we are going to create a simple Python project, in VS Code, to create a function to calculate the factorial of a number.
You will need the following if you want to try this yourself:
- VS Code installed
- GitHub Copilot extension installed in VS Code
- GitHub Copilot Chat extension installed in VS Code
- An active GitHub Copilot subscription
Let's run through the following steps:
-
Open VS Code and select the GitHub Copilot Chat extension. This will open a pane in VS Code with a text box for you to start chatting with GitHub Copilot. GitHub Copilot Chat has a variety of slash commands you can use, as shown in Figure 1.
 [Click on image for larger view.] Figure 1: Slash Commands
[Click on image for larger view.] Figure 1: Slash Commands
With these commands you can ask GitHub Copilot to explain code to you, fix errors in your code, or even start a new project for you.
-
We are going to use the /new command to create a new workspace for our python application. Figure 2 shows you the information I typed into the chat window, and the GitHub Copilot response.
 [Click on image for larger view.] Figure 2: Create a Python Application
[Click on image for larger view.] Figure 2: Create a Python Application
You can see the workspace it is proposing to create for me. This looks good, so I click Create Workspace. It prompts me on where to create it, and then it creates the factorial.py and README.md files.
-
Now here is where things get cool. First off, it creates the factorial.py file, shown in Figure 3.
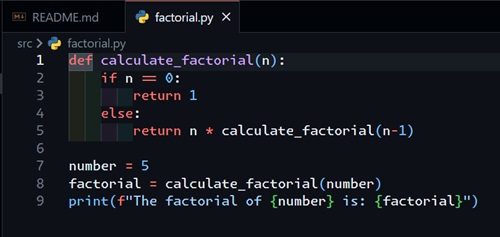 [Click on image for larger view.] Figure 3: Creating the Factorial.py File
[Click on image for larger view.] Figure 3: Creating the Factorial.py File
This looks very similar to what GitHub Copilot code completion did for us in February.
But what is also cool is that it creates a README.md file, explaining what this project and code do, partially shown in Figure 4.
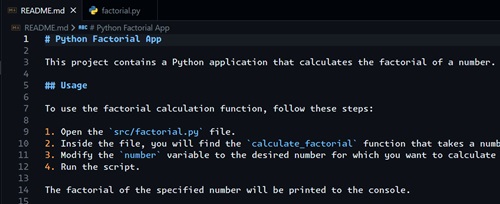 [Click on image for larger view.] Figure 4: Creating README.md File
[Click on image for larger view.] Figure 4: Creating README.md File
-
Now, maybe I don't quite understand the code in Figure 3. I can highlight the code, then back over in GitHub Copilot Chat, I can ask it to explain the selected code (Figure 5).
 [Click on image for larger view.] Figure 5: Explain the Selected Code
[Click on image for larger view.] Figure 5: Explain the Selected Code
And check it out, it not only explained the code to me, it also suggested I add input validation to handle invalid inputs, like negative numbers, and even provided me the updated code for that scenario.
This is just a simple introduction to GitHub Copilot Chat, using only a couple of basic commands. I've used this to create entire applications in programming languages that I have no experience with. And just wait until you start running into error messages that you don't understand. I've been able to feed the error message to GitHub Copilot Chat, and it has quickly come back with suggestions to resolve the error messages.
The more context you can provide GitHub Copilot Chat, the better it will do in answering your questions. For example, it will use all the information you have previously entered in the current chat, as well as the tabs you have open in VS Code.
Conclusion
GitHub Copilot Chat represents a significant leap forward in the realm of AI-assisted coding. By providing real-time, context-aware assistance directly within VS Code, it transforms the development experience, making it more efficient and enjoyable. This tool not only enhances productivity but also fosters a deeper understanding of coding practices, thereby improving the quality of the code produced.
As AI continues to evolve, tools like GitHub Copilot Chat will become increasingly integral to the software development process. They empower developers to tackle more complex problems with confidence, streamline the coding workflow, and ensure adherence to best practices. Embracing these advancements will undoubtedly pave the way for more innovative and effective software solutions in the future. Whether you're a seasoned developer or just starting, integrating GitHub Copilot Chat into your workflow can significantly enhance your coding capabilities and efficiency.
Happy Coding!
Posted by Mickey Gousset on 06/24/20240 comments